データモデリングとは?最新の基本概念と実務への応用を解説!

情報システムの構築やデジタルトランスフォーメーションを進める際、データモデリングは欠かせない技術です。この技術を正確に理解することで、データから価値を引き出し、ビジネスの競争力を高めることができます。特に、情報システム部門の方や、デジタル資産の最適化を図りたいと考えている方にとって、参考になれば幸いです。この記事では、データモデリングの基本概念と最新の応用について詳しく解説します。データモデリングの基礎から実践的なステップ、そして未来への展望までをカバーしますので、ぜひ最後までお読みください。
- データモデリングとは、ビジネスプロセスをデータ形式で表現し、データベースの設計に役立てる手法です。
- データモデリングには、概念モデル、論理モデル、物理モデルの3つ基本モデルがあります。
- 生成AIや大規模言語モデル(LLM)を活用したデータモデリングが急速に広がり、自然言語からのスキーマ生成、データ品質の自動チェック、モデル最適化の提案などに活用されています。
-
 岡田 祥ネットソリューション事業本部 ネットインテグレーション事業部
岡田 祥ネットソリューション事業本部 ネットインテグレーション事業部2018年、富士ソフト株式会社へ入社。Windowsクライアントアプリケーション開発やWebアプリケーション開発を担当していたが、近年はSnowflakeを使用したデータ分析基盤の構築なども手掛ける。「SnowPro Advanced: Architect」などの資格を保持。
データモデリングとは?目的と基本概念を理解する

データモデリングは、情報システムでデータの構造を視覚化し、管理するためのプロセスです。目的は、データの効率的な整理や取り扱いを可能にし、業務全体の効率を向上させることです。基本概念として、データのエンティティや属性、リレーションシップ(関係)を特定し、業務要件を反映したデータベースの設計を行います。これにより、必要な情報を迅速に取得し、ビジネスインテリジェンスを強化することが可能です。
データモデリングの定義と役割
データモデリングとは、ビジネスプロセスをデータ形式で表現し、データベースの設計に役立てる手法です。情報システムの基盤となるデータ構造を視覚化し、効率的なデータベース管理を実現します。具体的には、データの種類や形式を明確にし、データの流れや相互関係を定義します。これにより、組織全体のデータ利用が最適化され、業務プロセスの改善が進みます。
概念モデル・論理モデル・物理モデルの違い
データモデリングには、概念モデル、論理モデル、物理モデルの三つがあり、それぞれ異なる役割を担っています。
概念モデルは主にビジネス要件を可視化し、重要なエンティティとその関係を明確にします。これにより、ビジネスの専門家がデータの構造を理解しやすくなり、業務プロセスの全体像をつかむ助けとなります。
論理モデルは、概念モデルを基に、より詳細なデータ型や属性を含めたデータベースの独立した論理構造を設計します。これにより、技術者が具体的なシステム要件に沿ったデータベースを構築しやすくなります。また、論理モデルの設計時に正規化を行うことで、データの整合性と一貫性を確保します。
物理モデルは、データベース管理システム(DBMS)に依存した具体的な設計を行います。ここでは、最適なパフォーマンスを実現するためのテーブル構造やインデックス設計を固めます。物理モデルを適切に設計することで、システムの高速性や安定性を確保することができます。これら三つのモデルを理解し適用することにより、より効果的なデータモデリングが可能になります。
スタースキーマなど基本構造の概要
スタースキーマは、データウェアハウスにおける代表的なデータ構造の一つです。このアーキテクチャでは、中心に位置するファクト(事実)テーブルを取り囲むように、複数のディメンション(分析軸)テーブルが配置されるため、“星”の形に見えることが特徴です。これは、ビジネスインテリジェンス(BI)ツールを用いた分析をより直感的に行う上で、重要な役割を果たします。
ファクト(事実)テーブルは、主にビジネス上の具体的な出来事やトランザクションに関するデータを格納します。このテーブルは、大量の数値データを持ち、クエリの高速化を可能にします。一方、ディメンション(分析軸)テーブルは、ファクト(事実)テーブルに対応する詳細情報を格納し、例えば期間、製品、地域などの文脈を提供します。これによって、データ分析はより豊かで意味のあるものになります。スタースキーマを活用することで、データから新たな知見を迅速に引き出し、ビジネス戦略の策定を支援することができます。
実務で使えるデータモデリングのステップ

データモデリングは、情報システムの構築に欠かせないプロセスです。特に、情報システム部門の方にとって、効率的なシステム設計とデータ活用を可能にします。この章では、データ分析を目的としたデータモデリングで役立つステップを具体的に紹介します。まず、業務要件からの概念モデル導出、次に論理モデル設計、最後に物理モデルへの展開について説明します。これらを理解することで、デジタルトランスフォーメーションに役立つ強固なデータ基盤を築けます。
業務要件から概念モデルを導くプロセス
概念モデルは、業務やビジネスの視点から必要な情報とその関係性を技術的な詳細抜きで整理するモデルであり、まず業務の目的や必要な情報を整理し、エンティティ間の関係性を明確にします。データ分析における概念モデルではファクト(事実)とディメンション(分析軸)を明確にすることが目的です。小売企業の在庫管理システムを例として考えてみると、以下のようになります。
ファクト(事実):在庫数量、入庫数量、出庫数量、在庫金額
ディメンション(分析軸):商品、倉庫、仕入先、日付
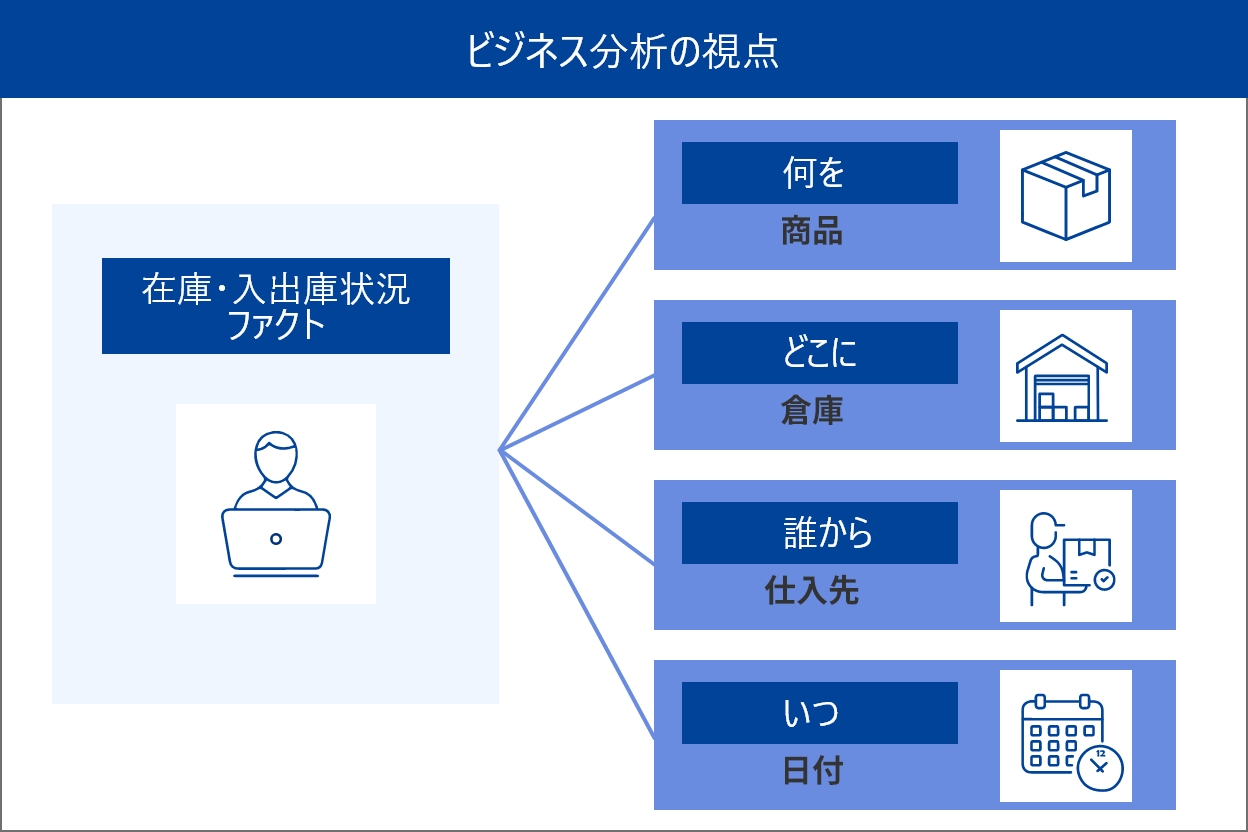
概念モデルをしっかり行うことで効率的な情報システムの構築が可能となり、デジタルトランスフォーメーションを推進する上での強力な基盤を築けます。
論理モデル設計の進め方
論理モデルは概念モデルを基に、データベースで扱える形に落とし込みます。属性(項目)やキー、正規化などを定義しますが、特定のDBMS(データベース管理システム)には依存しません。前ステップで作成した概念モデルからスタースキーマの構造に落とし込むと以下のようになります。
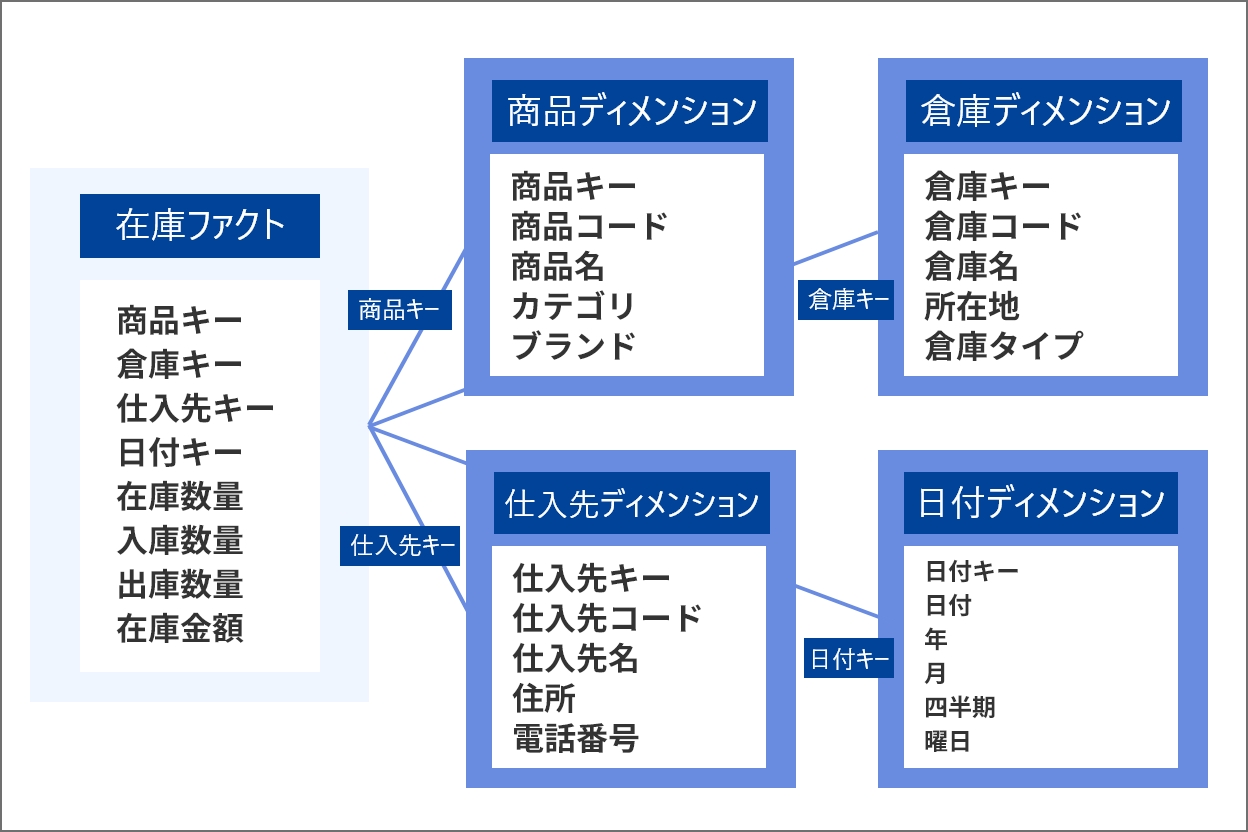
ここでは正規化やリレーションシップの種類(1対多、多対多など)を明確にします。
物理モデルへの展開
物理モデルへの展開は、論理モデルを実際のデータベース構造に変換するステップです。このプロセスでは、具体的なデータベース管理システム(DBMS)の特性を考慮し、最適化されたテーブル作成やインデックス設計を行います。例えば、MySQLを使用する場合、InnoDBストレージエンジンを選択してトランザクションの安全性や参照整合性を確保することができます。

また、特定のテーブルにインデックスを設定することにより、データ検索の速度を劇的に向上させられます。選択したDBMSに応じて、キャッシュ機能や並列処理の設定を最適化することで、システムパフォーマンスがさらに改善します。効果的な物理モデル設計は、システムの安定性や応答性に直結するため非常に重要です。これにより、ユーザー企業の情報システム部門の方がスムーズなシステム運用を実現できます。
データモデリングが効果を発揮する活用例

データモデリングは情報システム構築やデジタルトランスフォーメーションにおいて多くの場面でその効果を発揮します。特に、ビジネスインテリジェンス(BI)やデータウェアハウス、業務システム、データ連携設計において、データの取り扱いを効率化し、情報の分析や価値の創出をサポートします。具体的な事例を見ていきましょう。
BI・データウェアハウスでのスタースキーマ適用例
スタースキーマはBIやデータウェアハウスの構築で大きな効果を発揮します。スタースキーマを用いることで、クエリの効率が向上し、意思決定に必要なデータを迅速に分析することが可能となります。この構造は、一つの中央ファクトテーブルと周囲に広がる複数のディメンションテーブルから成り立ち、直感的な分析が可能です。このようなスキーマの適用により、データ分析の柔軟性が向上し、企業がより効果的なビジネス戦略を策定する助けとなります。
業務システムやデータ連携設計での活用例
業務システムやデータ連携設計では、データモデリングが異なるシステム間のデータ整合性を確保するのに役立ちます。データモデリングを活用することで、システム統合がスムーズになり、業務プロセス全体の効率性が向上します。特に、ユーザー企業の情報システム部門では、データの一貫性がビジネス価値の最大化に直結します。このアプローチにより、無駄が削減され、データ駆動型の意思決定プロセスが促進されるのです。これにより、業務の迅速化と精度向上が期待できます。
データモデリング習得のポイント
データモデリングを習得するためには、理論と実践の両方が重要です。まず、基礎知識をしっかり理解し、データベース設計の基本を押さえることが求められます。さらに、演習や実際のプロジェクトを通じてスキルを磨くことが効果的です。これらの方法により、より実務に即したスキルを習得し、デジタルトランスフォーメーションを支える力となります。基礎を固めることで、複雑な課題にも対応可能な柔軟な設計が可能になります。
理解すべきデータベース設計の基礎知識
リレーショナルデータベースの基本概念(テーブル、主キー、外部キー、正規化など)を理解することが出発点になります。エンティティとリレーションシップの概念、一対多や多対多といった関係性の表現方法も重要です。正規化は第一正規形から第三正規形までの正規化理論を学び、その上でパフォーマンスやメンテナンス性を考慮して、いつ非正規化すべきかを判断できる力が求められます。ER図作成ツール(ERDツールやUMLツールなど)の使い方を習得し、他者が理解しやすいドキュメントを作成する技術も必要になります。
業務フローやビジネスルールの理解
技術的なスキルだけでなく、業務フローやビジネスルールを理解し、それをデータ構造に落とし込む能力も重要です。ステークホルダーとのコミュニケーションを通じて要件を引き出すスキルも含まれます。
これからのデータモデリング2026年に注目すべき潮流

データモデリングの分野は、技術の進化に伴い変革と進化が続いています。2026年、情報システム部門の方々が注目すべき潮流には、データガバナンスの強化とデータプライバシーの重要性の増大があります。PETs(プライバシー強化技術)との連携は、データの安全性を確保しつつ、効率的な情報利用を可能にします。また、AIの高度化により、データ処理と分析の自動化が進むことで、より迅速に意思決定ができる環境が整うでしょう。
データガバナンスやPETsなどとの連携視点
データガバナンスとは、データの品質、セキュリティ、利用に関する管理プロセスです。ビジネスのデジタル化が進む中、データガバナンスの役割がますます重要になっています。プライバシー強化技術(PETs)との連携により、安全性を高めたデータ活用が可能です。ユーザー企業は、データの管理を徹底することで、信頼性の高いシステム構築を目指すべきです。
AIとLLMの統合
生成AIや大規模言語モデル(LLM)を活用したデータモデリングが急速に広がっています。これらの技術は、自然言語からのスキーマ生成、データ品質の自動チェック、モデル最適化の提案などに活用されており、データエンジニアやアナリストの作業効率を大幅に向上させています。
リアルタイムデータアーキテクチャ
ストリーミングデータとバッチデータを統合的に扱うアプローチが主流になりつつあります。Apache IcebergやDelta Lakeなどのテーブルフォーマットを使用した、リアルタイム分析に対応したデータレイクハウスアーキテクチャの採用が進んでいます。
データモデリングの要点まとめ
データモデリングは、デジタルトランスフォーメーションを推進する企業にとって重要です。情報システム部門の担当者は、データを価値に変えるために、新しい概念と実務への応用を押さえることが求められます。概念モデルから物理モデルへ展開する際のプロセスや、BI・データウェアハウスでのモデル適用事例を理解することが肝心です。
また、データガバナンスやプライバシー強化技術(PETs)との連携を念頭に置くことが重要です。AIやクラウド時代における柔軟な設計が求められるため、適切なツールの選定とデータベースの基礎知識をしっかりと習得することがポイントです。これらの要点を理解することにより、データから新たな価値を創出できるでしょう。
富士ソフトではSIerとしての技術力を基盤に、お客様のニーズに応じた具体的かつ実践的なデータ利活用の解決策をご提案いたします。お気軽にご相談ください。
※記載の会社名、製品名は各社の商標または登録商標です。




