

生成AIの活用は進んでいますか?医療系の組込みソフトウェア開発をしている中川です。
昨今、生成AIを活用したRAG(検索拡張生成)がAWS、Microsoft、Google Cloud等の各クラウドベンダーから提供されています。
本コラムでは、Generative AI Use Cases JP(GenU)を使用して、Amazon KendraとAmazon Bedrock Knowledge Basesの違いについて実動を交えながら解説します。これらのツールの効果的な利用方法に焦点を当てています。なお、環境構築に関しては別のコラムで詳しく解説していますので、以下のリンクをご参照ください。
GenUを通じて、生成系AIのアプリを使用する | FUJISOFT Technical Report
そもそもRAGとは
RAGとは、大規模言語モデル(例:ChatGPT)によるテキスト生成に、外部情報(社内文書など)の検索を組み合わせることで、回答精度を向上させる技術です。
簡単に言えば、「特定の情報に詳しい大規模言語モデル」といったイメージです。
AWSでRAGが使用できるサービス
情報の更新が非常に速いため、実際には多くの選択肢がありますが、本コラムでは代表的な2つのサービスに絞って紹介します。
- Amazon Kendra
https://aws.amazon.com/jp/kendra/
特徴
・セマンティック検索に対応:自然言語での問い合わせに対応し、適切な検索結果を返します。
・外部情報に対応:テキストデータだけでなく、PDFファイルなどの非構造化データも利用可能です。
※対象ドキュメントは頻繁に更新されるため、定期的な確認をおすすめします。
- Amazon Bedrock Knowledge Bases
https://aws.amazon.com/jp/bedrock/knowledge-bases/
特徴
・Default: ⼀定のトークン数ごとにチャンク分割(デフォルトは300トークン)
・Hierarchical:子チャンクと親チャンクを用意し、検索精度と情報漏れ防止を両立
・Semantic:⽂章の意味を考慮してセクション単位でチャンク分割
※チャンク:テキストを意味的または構文的なまとまりで分割した小さな単位を指します。これが大きすぎると検索をかけた時に必要な部分が埋もれてしまい、小さすぎると逆に検索に引っ掛かりすぎて意図とは違う内容を取得してしまいます。そのため、チャンク分割はRAGの精度を上げるためにも有用な策となります。

GenUでRAGを有効にする方法
cdk.jsonは、AWS CDKプロジェクトの設定ファイルで、アプリケーションのエントリーポイントやデプロイ時の動作を定義するファイルです。 このファイルのcontextセクションでは、Amazon KendraやAmazon Bedrock Knowledge Basesなど、使いたい対象の拡張機能のオンオフ設定ができます。
具体的には、
● ragEnabled: RAG機能の有効/無効
● kendraIndexArn: Kendraインデックスの指定
● ragKnowledgeBaseEnabled: Amazon Bedrock Knowledge Basesの有効/無効
● agentEnabled: エージェント機能の有効/無効
● mcpEnabled: Model Context Protocolの有効/無効
など、プロジェクトで利用する機能をtrue/falseや具体的な値で制御できます。
RAG機能で使用されるドキュメントは、packages/cdk/rag-docs/docs に保存されているデータです。
※RAGで参照されるファイル
https://github.com/aws-samples/generative-ai-use-cases/blob/main/packages/cdk/rag-docs/docs/bedrock-ug.pdf
(2025/08/05時点)
- Amazon Kendraの設定
以下の手順で再デプロイとデータソースの同期を行います。
{
"context": {
"ragEnabled": true,
"kendraIndexLanguage": "ja"
}
}
npm run cdk:deploy を実行。
① Amazon Kendraのコンソール画面を開く
② [generative-ai-use-cases-index]を選択
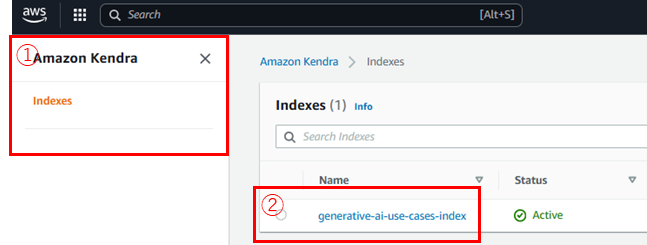
③ [Data sources]を選択
④ [s3-data-source]を選択
⑤ [Sync now]をクリック

※Amazon Kendraは月額約820ドル程度のコストがかかるため、利用時はご注意ください。
- Amazon Bedrock Knowledge Basesの設定
以下の手順で再デプロイとデータソースの同期を行います。
{
"context": {
"ragKnowledgeBaseEnabled": true,
}
}
npm run cdk:deploy を実行。
① Amazon Bedrock Knowledge Bases のコンソール画面を開く
② [generative-ai-use-cases-jp]を選択
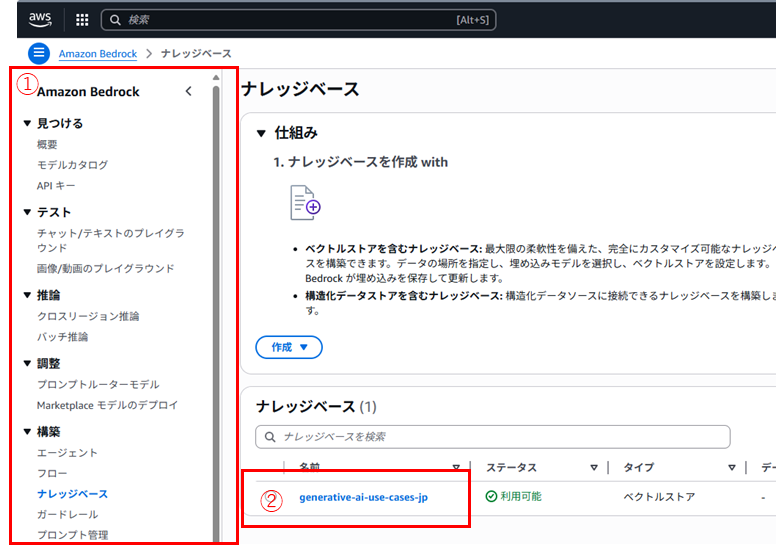
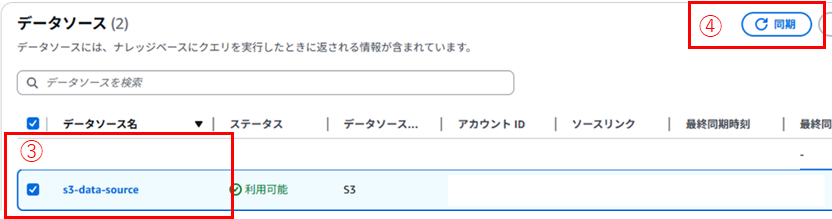
③ [s3-data-source]を選択
※このデータソースはGenUがデフォルトで作成したものです。
チャンク分割方法を変更して別のデータソースを作成することも可能です。
④ [Sync]をクリック
※チャンク分割方法は、packages/cdk/lib/rag-knowledge-base-stack.tsにコメントアウトされた形で準備されており、簡単に切り替えが可能です。
ただし、チャンク分割方法を変更する際は、現時点では新たなデータソースの作成が必要です。
※Amazon Bedrock Knowledge Basesは、Amazon OpenSearch Serviceを使用するので1日あたり約5ドルのコストがかかります。
GenUに搭載されているPDFファイルをデータソースとして、同じ質問を用いて実動検証を行いました。
Amazon Kendraの実動
Amazon Kendraでは、入力された自然言語の意味を理解して、その意味に沿った回答をするセマンティック検索の技術が使われています。今回は入力された質問を解釈して、Amazon Bedrockで設定可能なパラメータの種類と、その設定方法をLLM側が回答してくれました。検索に使われたページを参照すると確かにそれらの情報が書かれています。
また回答を作成する能力はAmazon Kendraにはないため、RAGチャットの下のプルダウンで選択している基盤モデルによって回答が作成されます。
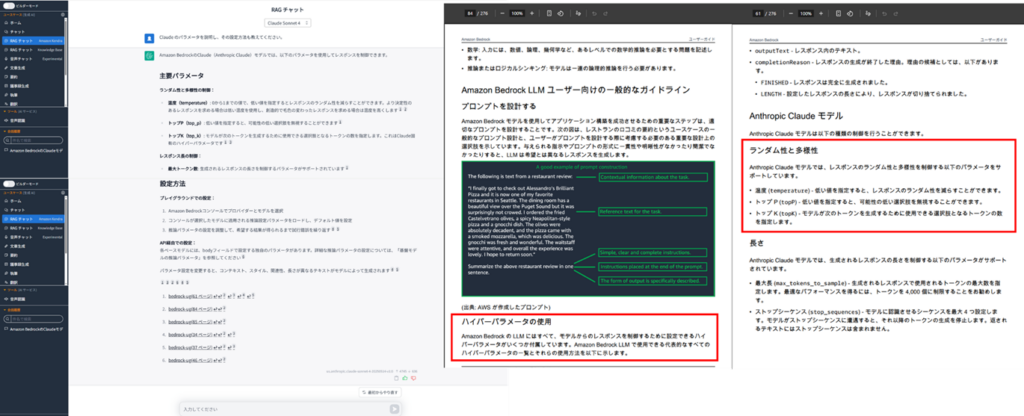
以下の3つのチャンク分割方式で検証を実施。
Amazon Bedrock Knowledge Basesの実動
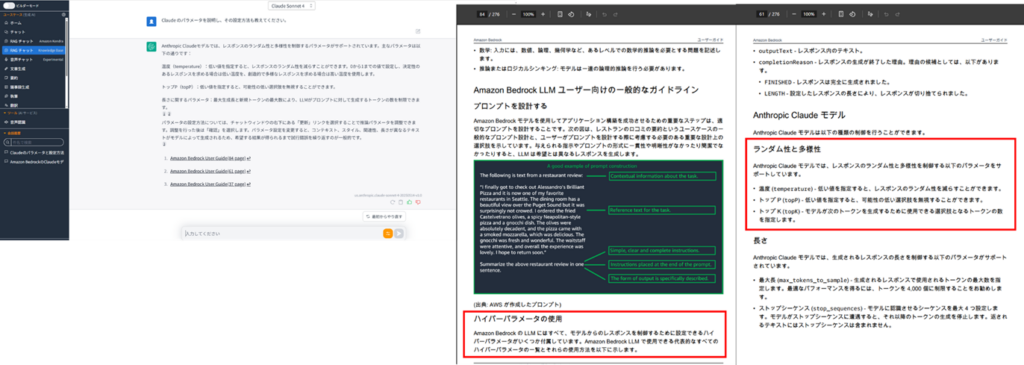
・Default
チャンキング戦略がDefaultの場合は、指定したサイズのトークンごとにチャンク分割します。今回は入力された質問に対して、検索に引っ掛かった部分(下記の赤枠)をLLMで人間が分かりやすい説明にした状態で返却されました。Amazon Kendraの結果と比べると、単純な検索能力しかないようにも感じますね。
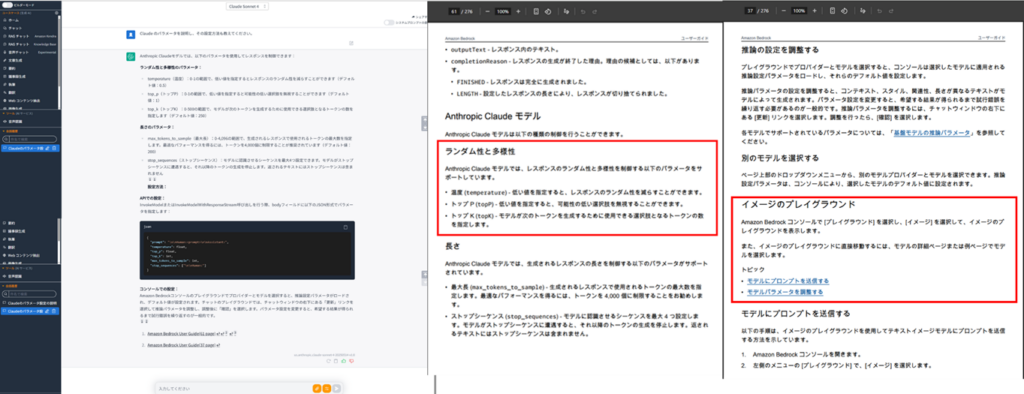
・Hierarchical
チャンキング戦略がHierarchicalの場合は、まずは子チャンクとして「パラメータ」に関する結果と「設定方法」に関する結果が引っ掛かっていることが、参照のリンクページから分かります。しかし、LLMの回答はAmazon Kendraの時と似たように充実した回答が返ってきています。これは赤枠部分の親となるテキストも解釈したうえで回答を作っているようにも見えます。
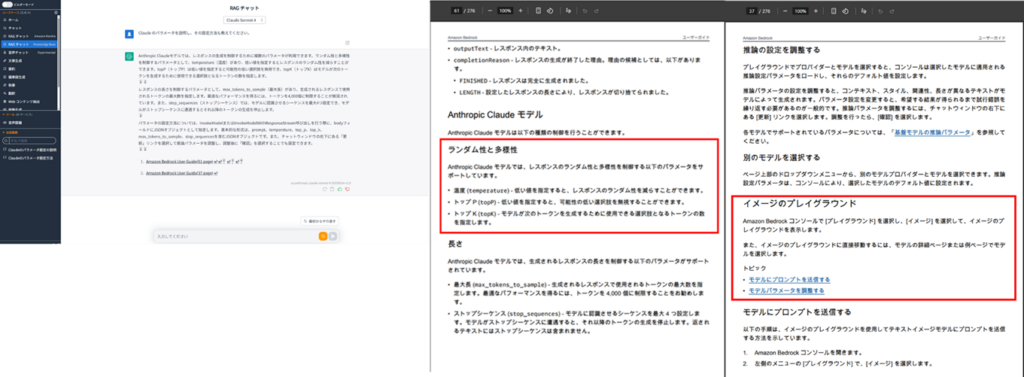
・Semantic
チャンキング戦略がSemanticの場合は、文章の意味を理解してチャンク分割します。参照のリンクページはHierarchicalの時と同じようですが、回答が違うようです。Hierarchicalの時と比べると、Semanticの時の方が温度とはどのようなパラメータなのか、トップPとはどのようなパラメータなのか、トップKとはどのようなパラメータなのかをより解釈してLLMが説明してくれているようにも感じます。
RAG検索の結果の違い
今回は、AWSが出しているBedrockの資料を検索対象としましたが、各自のドキュメントを検索対象とした時はチャンクのサイズが想定と変わる可能性がありますが、それぞれのRAGの特性を理解しながら調整することで、期待する精度に近づくかと思います。
・Amazon Kendra
入力された質問を解釈して、その意味に沿った回答をするセマンティック検索を行う。
検索結果はLLMがまとめて利用者への回答を作成する。
・Amazon Bedrock Knowledge Bases(Default)
指定したサイズのトークンごとにチャンクで入力された質問を検索する。
検索の結果は、検索に引っ掛かったチャンクが返却され、LLMがそれを受け回答を作成する。
※今回のGenUでは標準機能をそのまま使っていたため、分かりにくかったかもしれませんが、検索に使用する基盤エンジンと回答の生成に使用する基盤エンジンは異なるものを使うことが可能です。
・Amazon Bedrock Knowledge Bases(Hierarchical)
質問に対して、子チャンクを検索する。
検索の結果は、子チャンクの親チャンクが返却され、LLMがそれを受け回答を作成する。
・Amazon Bedrock Knowledge Bases(Semantic)
入力された質問を検索する。
検索文章は意味のあるまとまりごとに分割されているため検索の結果は、検索したチャンクに近しい結果が返却され、LLMがそれを受け回答を作成する。
まとめ
本コラムでは、Amazon KendraとAmazon Bedrock Knowledge Basesの違いについて、実動を交えながら解説しました。それぞれのツールは、異なる特徴と利点を持つため、ニーズに応じた選択が重要です。GenUを活用することで、これらのツールの効果的な利用方法を学び、実際の業務に活かすことが可能です。環境構築に関する詳細は別のコラムで紹介していますので、そちらもぜひご参照ください。



