ノーコードで、Cloud StorageからイベントドリブンでBigQueryにデータを格納する
- 1. はじめに:本記事内容のご紹介
- 2. イベントドリブンとは?
- 3. BigQueryへのCSVファイル格納方法
- 4. BigQueryのData Transfer Service(DTS)とは
- 5. DTSのイベントドリブン転送構築の方法
- 6. まとめ
自己紹介
2024年に富士ソフト株式会社に入社しました、情報ソリューション事業部DXアプリケーション部所属の高橋 遼香(たかはし はるか)です。2025年5月からGoogle Cloudのチームに配属され、Google Cloudに触れ始めました。実務では、BigQueryやCloud Functionsなどを使用した経験があります。
今後もGoogle Cloudを使いたい方向けに、お役に立てるようなブログを書いていきたいです☺
1. はじめに:本記事内容のご紹介
本記事では、BigQueryの「Data Transfer Service(DTS)」を使用して、Cloud StorageからイベントドリブンでBigQueryにCSVファイルを転送する方法をご紹介します。この記事は、以下のようなお悩みを持つ方におすすめです。
- ・BigQueryにCSVファイルを格納したい…
- ・Cloud StorageにCSVファイルを置いたら、自動でBigQueryに転送してほしい。
- ・コードの知識が無いけど、BigQueryに転送するシステムを作りたい!
上記のようなお悩みを持つ方に、この記事が少しても参考になれば幸いです。
2. イベントドリブンとは?
「イベントドリブン(Event-driven)」とは、システムやプログラムの動作が、特定の「イベント(事象)」の発生によって開始・制御される設計手法やパラダイムのことです。
イベントドリブンの仕組み
イベントドリブンなシステムでは、システムが外部からの入力を受け取るのをひたすら待つのではなく、特定のイベントが起きるのを待ちます。イベントが発生すると、それに対応する処理(イベントハンドラ)が自動的に実行されます。
一般的な例を挙げると、以下のような流れになります。
イベントの発生: ユーザーがボタンをクリックしたり、センサーがデータを検知したり、ファイルがアップロードされたりする。
イベントの通知: 発生したイベントがシステム内の「イベントキュー」や「イベントバス」と呼ばれる場所に送られる。
イベントハンドラの実行: イベントキューからイベントが取り出され、そのイベントに対応する特定の処理(イベントハンドラ)が呼び出されて実行される。
イベントドリブンの利点
高い応答性: ユーザーのアクションや外部の事象に即座に反応できるため、システムがスムーズに動きます。
非同期処理: イベントの発生と処理が切り離されているため、あるイベントの処理中に他のイベントを待機させることができます。これにより、システム全体がブロックされることなく、複数の処理を効率的に並行して進めることができます。
疎結合: システムの各コンポーネントがイベントを介して通信するため、直接的な依存関係が少なくなり、柔軟性が高まります。これにより、コンポーネントの追加や変更が容易になります。
具体的な例
ユーザーインターフェース (UI):
ユーザーがボタンをクリックする、コンソール画面から何かを操作する、といったものが「イベント」です。このイベントをトリガーとして、画面表示の変更、データの保存、次の画面への遷移といった処理が実行されます。
このように、イベントドリブンなシステムは、ユーザーの操作からIoT、マイクロサービス、金融取引システムなど、さまざまな分野で広く利用されています。
3. BigQueryへのCSVファイル格納方法
Google Cloud Consoleを使用
最も簡単で直感的な方法です。小規模なファイルや、一度きりのデータ取り込みに適しています。
データセットの縦3点リーダー(アクションを表示)>テーブルを作成>ソースでCloud Storageやローカルに存在するCSVファイルを選択
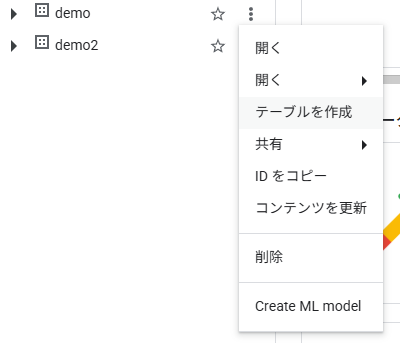
BigQueryのコンソール(スタジオ)画面

テーブル作成時のデータソース選択画面
上記の手順で、選択したCSVファイルを元にBigQueryテーブルを作成できます。
bqコマンドラインツールを使用
Google Cloud SDKに付属するbqコマンドを使用して、ターミナルから操作する方法です。GCPのコンソール画面上部にある、Cloud Shellでも同様に操作が可能です。コマンドを実行することにより、ローカルファイルやCloud Storageにあるファイルを読み込むことができます。
右上の□がCloud Shell起動ボタンである。
上記のように、データセット名、テーブル名、CSVファイルのパス、スキーマ情報などを指定して実行します。
Cloud Functionsを使用
BigQueryのAPIをプログラムから直接呼び出す方法です。複雑なデータパイプラインの構築や、ETL(抽出・変換・読み込み)処理に利用されます。PythonのBigQueryクライアントライブラリなどを使って、CSVデータを読み込むジョブを作成・実行します。
柔軟性が高く、データの加工や前処理を含めた独自のワークフローを構築できますが、プログラミングの知識が必要です。
BigQueryのData Transfer Service(DTS)を使用
今回の記事において、メインで取り扱う方法です。この方法によって、Cloud Storageに置いてあるCSVファイルを、BigQueryに転送できます。詳しくは以下に説明します。
4. BigQueryのData Transfer Service(DTS)とは
BigQuery Data Transfer Service (DTS) は、さまざまなソースからBigQueryへのデータ転送を自動化・管理するフルマネージドなサービスです。
主な機能と特徴
自動化された定期転送:
手動でファイルをアップロードする代わりに、設定したスケジュールに従って、データを自動的にBigQueryに転送できます。日次、週次、月次といった頻度を設定可能です。
イベントドリブンの転送が可能:
イベントドリブン転送は、2025年5月29日のアップデートで正式にサポートされました。例えば、Cloud Storageにファイルが置かれたら(イベント)、それをトリガーとしてBigQueryへの転送を行うことができます。その方法については、次の項目で詳しく説明します。
多様なデータソースへの対応:
Google Cloud Storageはもちろん、Amazon S3、MySQL、YouTube Analyticsなどの外部サービスからもデータを直接BigQueryに取り込めます。
コーディング不要:
GUIベースのコンソールで設定が完結するため、複雑なコードを書く必要がありません。
スケーラブルで信頼性が高い:
Googleがインフラを管理するため、大量のデータを効率的に転送でき、転送失敗時の再試行なども自動で行われます。
どのような場合に使用するか?
DTSは、定期的に更新されるデータを分析したい場合に特に役立ちます。
マーケティング分析:
Google AnalyticsやGoogle AdsのデータをBigQueryに取り込むことで、詳細なユーザー行動分析や広告効果測定を行う。
データ統合:
複数のプラットフォーム(ECサイトの売上データとCRMデータ)をBigQueryに集約し、一元的なデータウェアハウスを構築する。
バックアップと同期:
BigQuery内のデータセットを別のリージョンに複製・同期する。
DTSを利用することで、データ転送の運用負荷を大幅に軽減し、より重要なデータ分析に集中できます。
5. DTSのイベントドリブン転送構築の方法
前提条件
1. 次のAPIを有効化しておきます。
・BigQuery Data Transfer API
・Cloud Pub/Sub API
2. Cloud Storage、Pub/Sub、BigQueryを触れる権限が付与されているユーザーを使用します。
3. Cloud Storageにデモ用のバケット、BigQueryにデモ用のデータセットとテーブルを作成しておきます。
4. service-○○○○@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com
というサービスアカウントに、「Pub/Sub サブスクライバー」という権限が付与されているか確認してください。
5. 今回のデモ用に、Pub/Subのトピックとサブスクリプションを作成しておきます。
Cloud Shell上で以下のように打ち込みます。

Cloud Storageにファイルが置かれたことをトリガーとして動くPub/Subのトピックを作成する
BUCKET_NAME:作成したバケット名
TOPIC_NAME:ここで作成されるPub/Subのトピック名

作成したトピックに関連付けられる、サブスクリプションを作成
イベントドリブンな転送の作成(記載の無いものは、基本デフォルトのままで作成しています)
BigQueryの「データ転送」から、Data Transfer Serviceの転送を作成します。
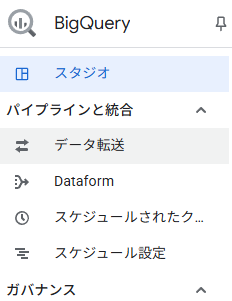
BigQueryのツールメニューから、「データ転送」を選択
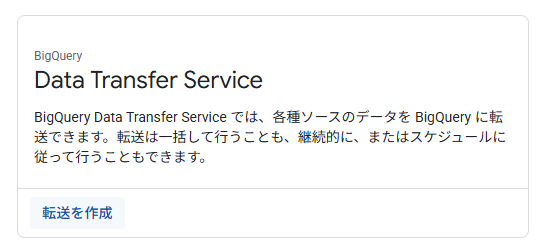
「Data Transfer Service」にて、「転送を作成」をクリック
ソースに「Cloud Storage」を選択。
転送構成名に任意の名前を記入。
繰り返しの頻度に「イベント ドリブン」を選択。
Pub/Subサブスクリプションに、前提条件で作成したサブスクリプションを設定。
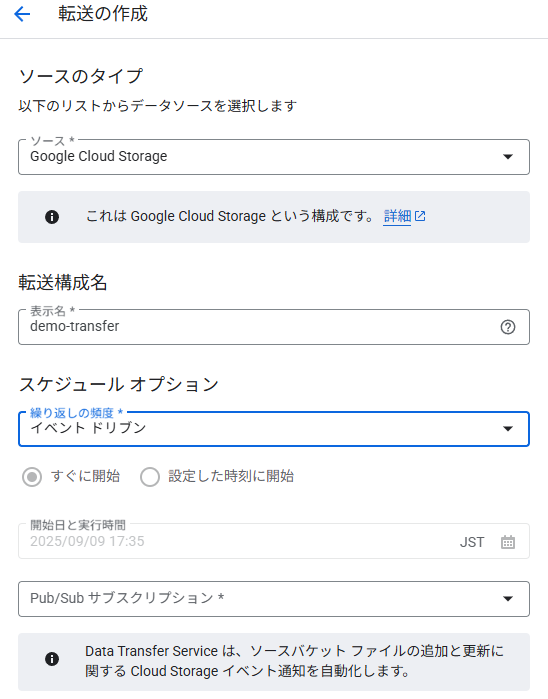
転送におけるデータソース選択、転送名、スケジュール頻度の設定を行う
転送先のデータセットを設定。
<データソースの詳細>では、宛先のテーブル、Cloud Storageのオブジェクトを選択。
Write preferenceは、以下2つの方法から選択できます。
APPEND(増分転送)…既存のデータに新しいデータを順次追加していく方式
MIRROR(切り捨て転送)…テーブルの内容を一度すべて削除してから、新しいデータを格納する方式
ファイルの形式は、ここではCSVファイルを選択。
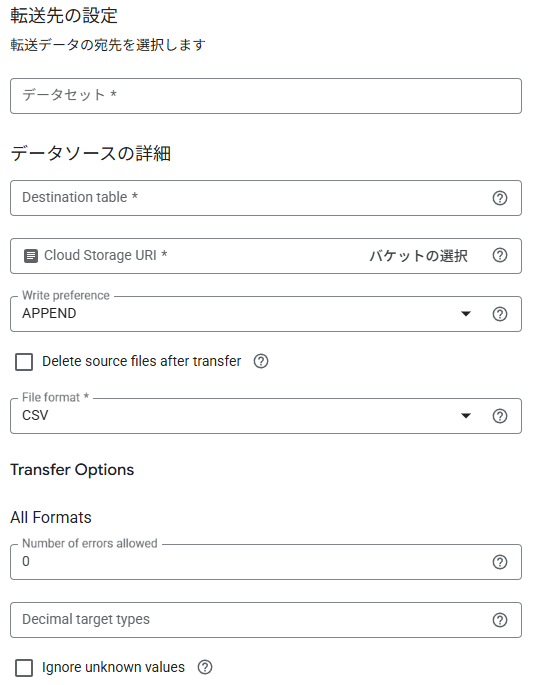
転送先とデータソースの設定画面
その他、CSVファイルをの設定を行います。
ここでは区切り文字の指定や、ヘッダーをスキップするかどうかなどを設定できます。
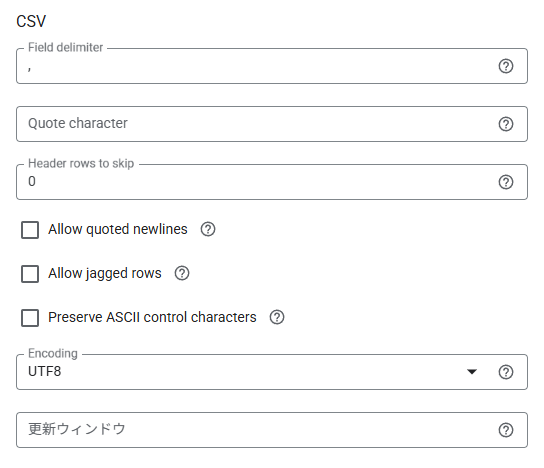
CSVファイルを転送する場合の、設定画面
転送の作成は以上です。
転送の実行
以下のようなCSVファイルを、Cloud Storageに置いてみます。

簡単なCSVファイル
そうすると、作成した転送が動き出します。
概要に「転送実行が正常に完了しました。」と表示されたら、きちんと格納されているかどうか、BigQueryを確認してみます。
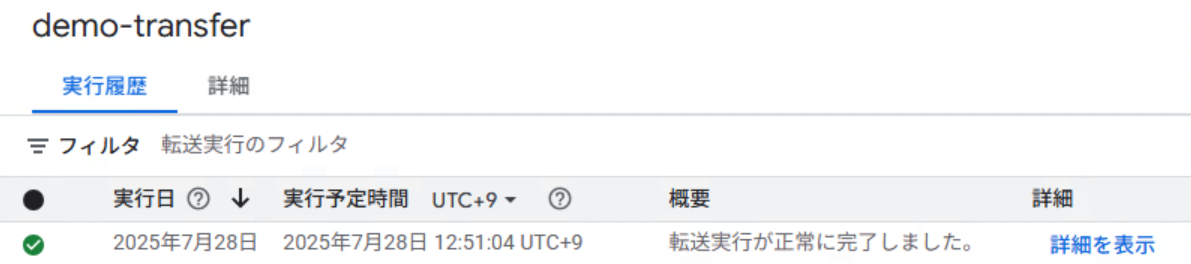
作成した転送の概要
SELECT文で確認してみると、実際にデータが転送されていることが確認できました。
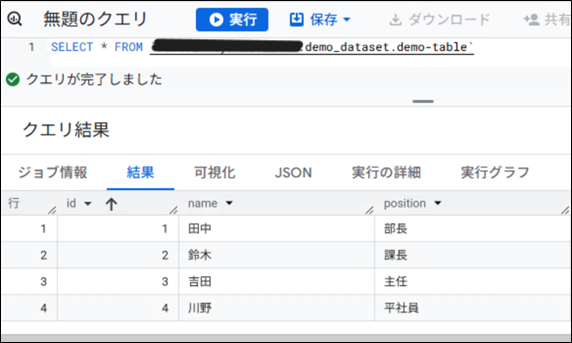
BigQuery上にデータが格納されているか確認
まとめ
本記事では、Cloud StorageにCSVファイルがアップロードされたことをトリガーとして、BigQueryに自動的にデータを転送する方法をご紹介しました。BigQuery Data Transfer Service (DTS) と Pub/Sub を組み合わせたアプローチでは、ほとんどコードを書くことなく、システムを構築することが可能です。
しかし、この方法では、データの書き込み方法が「追記 (APPEND)」と「上書き (MIRROR)」の2パターンに限定されます。もし、CSVファイルの内容を細かく加工したい場合や、書き込み方法をより柔軟に制御したい場合は、Cloud Functionsを利用したデータ転送を検討されることをお勧めします。Cloud Functionsを使用することで、要件に合わせた詳細な処理を実装できます。要件に合わせて、最適なデータ転送方法をお選びください。
最後までお読みいただき、誠にありがとうございました。この記事が、皆様のデータ分析の一助となれば幸いです。